Kubeflow — a machine learning toolkit for Kubernetes
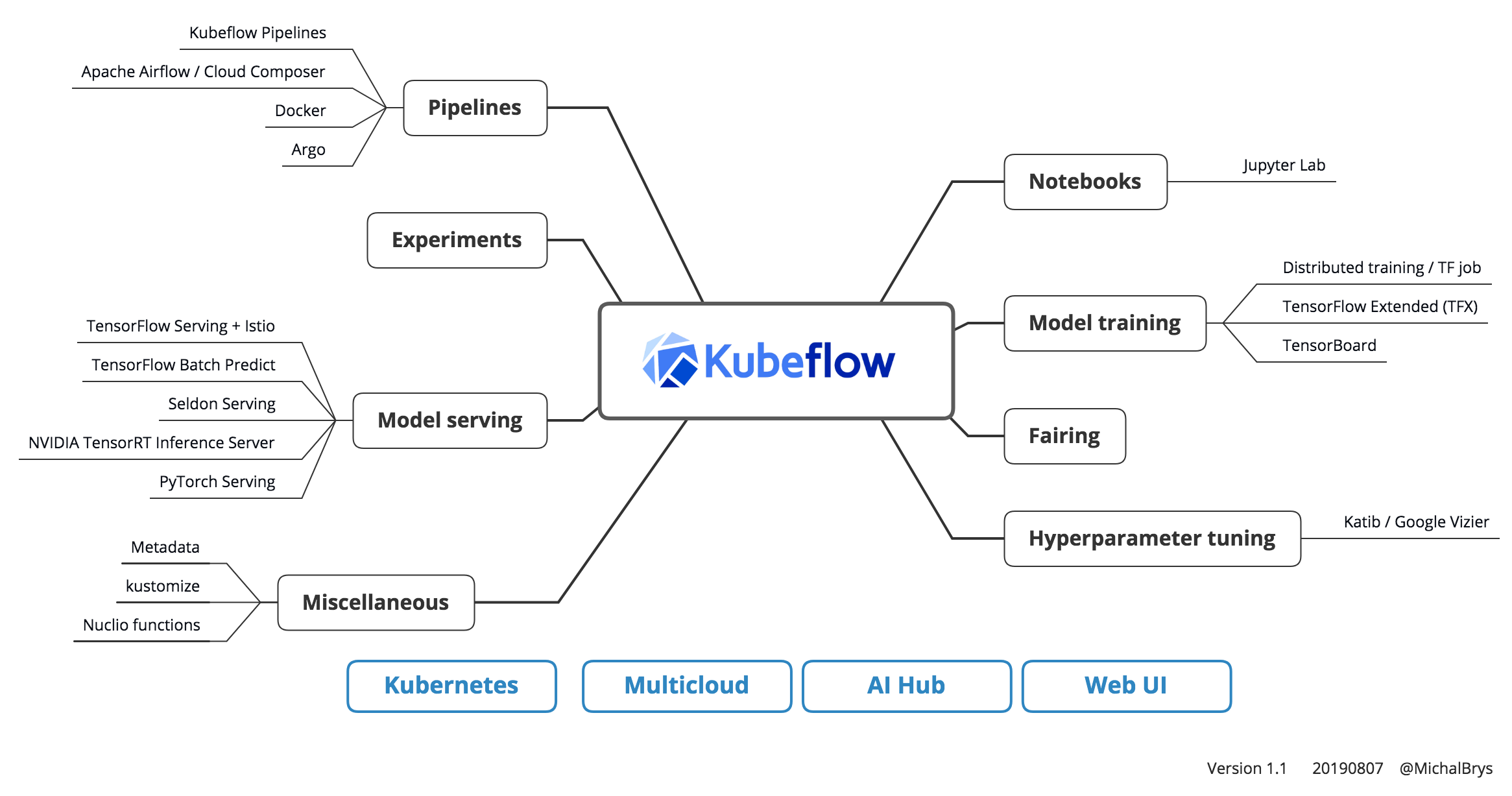
Kubeflow components map
{kind=link}
What is Kubeflow? It’s an open-source project integrating the most popular data science tools in one place. The main concept is to streamline build machine learning applications — from the prototype to the production. With Kubernetes under the hood, it’s an exciting toolkit that can make Data Scientists and Data Engineers life easier. This article is a subjective introduction to Kubeflow from a data scientist perspective.
Kubeflow components out-of-the-box
Once you have a running Kubeflow instance, you will get integrated components that allow you to build machine learning models and put them into production.
Notebooks
Notebooks became an industry standard for prototyping machine learning models and sharing them across the teams. In Kubeflow, you can quickly deploy a Jupyter Lab instance and start creating your ML models.
Model training
Kubeflow has integrated multiple options for model training. From local training in Jupyter Notebook, through managed services like Google Cloud AI Platform (formerly known as Cloud Machine Learning Engine) to custom distributed training with TensorFlow Training (TFJob). That selection fits a lot of complex real-life scenarios. If you’re are using the Tensorflow framework, there are a lot of useful features available. You can easily use TensorBoard or TensorFlow Model Analysis (TFMA) to analyze your model.
Fairing
Kubeflow Fairing is a Python package that lets you train the ML model in a hybrid cloud environment. You can choose if you want to train your model locally (i.e., in the Jupyter Notebook) or in the cloud. In the second scenario, Fairing will build a Docker container and deploy it to Kubeflow or AI Platform for training.
Hyperparameter tuning
Kubeflow has integrated Katib — a hyperparameter tuning framework, that implements Google Vizier and runs on Kubernetes.
Pipelines
Kubeflow Pipelines are a new approach to build end-to-end ML workflow. Every step of a pipeline is a Docker container, and the pipeline is defined in a .yaml file (using Argo). It means portable and scalable pipelines that you can deploy to the Kubernetes cluster. It also cuts short the whole workflow from the model prototype to the production.
Experiments
Kubeflow offers an easy way to compare different runs of the pipeline. I.e., you can create the pipeline with model training. Then run it multiple times with different parameter values, and you’ll get accuracy and ROC AUC scores for every run compared. Plus a lot more under “Compare runs” view.
Model serving
Out-of-the-box there are multiple ML models serving options available: TensorFlow Serving + Istio, TensorFlow Batch Predict, Seldon Serving, NVIDIA TensorRT Inference Server, PyTorch Serving.
Cloud-native
Kubeflow is a cloud-native project. You can deploy it using different cloud platform providers: Google Cloud Platform (GCP), Amazon Web Services (AWS) and Azure. Also, you can install it on your local machine or on-prem infrastructure.
Try it!
You can start with MiniKF — a local Kubeflow deployment that will run everything on your laptop. Note: downloading the vagrant file could take some time depending on your Internet connection speed.
Learn more
As Kubeflow is an open-source project, you are welcome to join a very supportive community and contribute to the source code. You can also check the tutorials and download resources from AI Hub.